Mempool
功能介绍
Mempool 的作用是收集合法的新交易,以向 Consensus 模块提供用于构建区块的交易集合。
具体来说,当节点成为本轮共识的 Leader 后,会向 Mempool 请求两个交易哈希集合用于构建共识提案。
一个交易哈希集合叫 ordered_tx_hashes,用于构建区块,参与本轮共识过程。
另一个叫 propose_tx_hashes,当 Mempool 中的交易数量超出一个区块所能放入的最大交易数时,
Mempool 会将全部或部分溢出的交易哈希放入propose_tx_hashes 中。
其他节点收到共识提案后,一方面检查 ordered_tx_hashes 所对应的完整交易是否都在本地 Mempool 中,如有缺失则向提案发起者同步交易。
如果在一定时间内无法收齐交易,则该提案视为非法。另一方面检查 propose_tx_hashes,同步缺失的交易,以提高待未来共识的交易的同步率。
当节点收集到合法共识提案的 2/3+ 的 Prevote 投票时,该提案即达成锁定条件,
Consensus 模块会通过 Mempool 拿到 ordered_tx_hashes 所对应的全部完整交易,并进行持久化,以保证共识安全。
当提案达成共识后,Mempool 要删除已达成共识的交易。
基于以上功能要求,在 Mempool 中有以下接口:
insert: 新交易通过必要的检查后插入 Mempool。详细的检查过程见交易的合法性检查。package: 从 Mempool 中打包两个交易哈希集合给 Consensus 用于构建共识提案。flush: 从 Mempool 中删除达成共识的交易。get_full_txs: 从 Mempool 中返回指定的交易哈希集合所对应的完整交易。ensure_order_txs: 确保ordered_tx_hashes所对应的完整交易都在 Mempool 中,对于缺失的交易会通过 Network 同步。sync_propose_txs: 检查propose_tx_hashes所对应的完整交易是否都在 Mempool 中,并同步缺失的交易。
交易的合法性检查
- 交易池是否已满
- 交易的字节大小是否超出阈值
- 交易的
cycles_limit是否超出阈值 - 交易的
chain_id是否正确 - 交易的
timeout是否在当前的合法窗口内 - 交易是否与交易池内已有的交易重复
- 交易是否与已上链的交易重复
- 交易的签名是否正确
- 交易的发起者的地址是否被授权
- 交易的发起者的账户余额是否足够支付最低交易费
与其他模块的调用关系
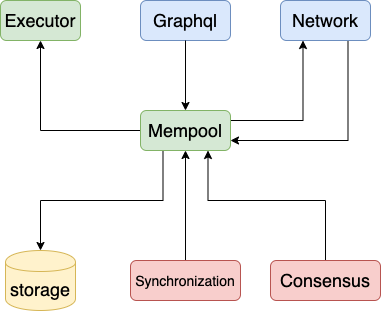
与 Graphql 的调用关系
- 用户使用 Graphql 客户端生成交易后,Graphql 会调用 Mempool 的
insert接口,将交易插入 Mempool。
与 Network 的调用关系
- 其他用户生成的,通过网络发来的交易,Network 会调用 Mempool 的
insert接口,将交易插入 Mempool。 - 当需要向其他节点获取指定的完整交易时,Mempool 会调动 Network 的
pull_txs接口,以获取指定的交易。 - 当其他节点请求指定的完整交易时,Network 会调用 Mempool 的
get_full_txs接口,以获得指定的交易。
与 Executor 的调用关系
- 在对要
insert的交易进行检查时,Mempool 会调用 Executor 的read接口,查询交易发起者的授权情况以及账户余额, 以完成相应的检查。
与 Storage 的调用关系
- 在对要
insert的交易进行检查时,Mempool 会调用 Storage 的get_transaction_by_hash接口用于查重。 - 在对要
insert的交易进行检查时,Mempool 会调用 Storage 的get_latest_block接口用于获取最新的区块, 进而获得必要的状态,用于chain_id的检查以及用于创建 Executor 以完成相应的检查。 - 在
package和flush时,Mempool 需要调用 Storage 的get_latest_block接口以获取最新的区块, 进而得到最新高度作为必要的状态以完成相应的任务。 - 在
get_full_txs时,Mempool 必要时会调用 Storage 的get_transactions接口以获得指定的完整交易。
与 Consensus 的调用关系
- 当节点是当前共识轮次的 Leader 时,Consensus 会调用 Mempool 的
package接口,以获得用于构造共识提案的两个交易哈希集合。 - 当节点收到共识提案时,Consensus 会调用 Mempool 的
ensure_order_txs接口, 检查提案中的ordered_tx_hashes所对应的完整交易是否都在 Mempool 中, 对于缺失的交易,Mempool 会调用 Network 的pull_txs接口获取对应的完整交易。 - 当节点收到共识提案时,Consensus 会调用 Mempool 的
sync_propose_txs接口, 检查提案中的propose_tx_hashes所对应的完整交易是否都在 Mempool 中, 对于缺失的交易,Mempool 会调用 Network 的pull_txs接口获取对应的完整交易。 - 当某个提案达成锁定条件时,Consensus 会调用 Mempool 的
get_full_txs接口, 以获得该提案中的ordered_tx_hashes所对应的完整交易,并进行持久化,确保被锁住的提案的完整的ordered_tx不会丢失。 - 当某个提案达成共识后,Consensus 会调用 Mempool 的
flush接口,以从 Mempool 中删除达成共识的交易。
与 Synchronization 的调用关系
- 当收到比最新高度高一个块的完整的合法区块后,Synchronization 会调用 Mempool 的
flush接口,从 Mempool 中删除达成共识的交易。
模块文件
mempool│ Cargo.toml│└───src│ context.rs // 获取交易的上下文,用于判断交易是本地 Graphql 发起还是来自网络│ lib.rs // 实现 Mempool 的所有对外接口│ map.rs // 实现并发 map│ tx_cache.rs // 实现 Mempool 的核心数据结构│└───adapter│ │ mod.rs // 实现 mempool 适配器,包含 Mempool 所需的所有外部资源│ │ message.rs // 定义 Mempool 的网络通信消息│ │└───test
具体设计
设计要求
- 按插入顺序打包。 为避免用户的合法新交易在交易池中始终无法被打包,并兼顾一定的公平性,交易池在打包时, 总体上是按照交易插入交易池的顺序打包。
- 支持高并发。 交易的插入需要满足高并发的要求,插入与打包可并行进行。
核心数据结构和实现思路
为了满足以上要求,我们用支持并发的 map 和 queue 结构共享存储交易数据,map 可快速查询和删除,而 queue 满足先入先出的打包要求。 Mempool 的核心数据结构如下:
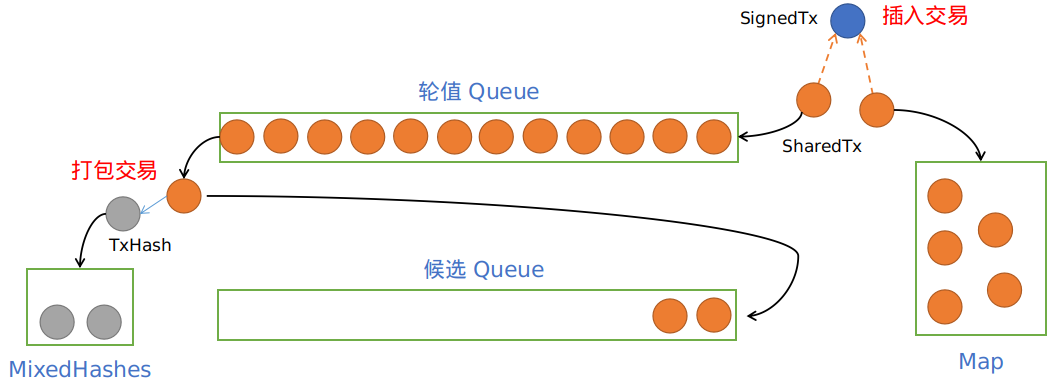
struct TxCache {/// 用 queue 实现先入先出的打包功能./// 用两个 queue 轮流存储交易. 一个 queue 当前轮值, 另一个则作为替补./// 打包时从当前轮值的 queue 中顺序打包.queue_0: Queue<SharedTx>,queue_1: Queue<SharedTx>,/// 用 map 完成高效的随机查询和删除交易.map: Map<Hash, SharedTx>,/// 指示当前轮值的 queue, true 为 queue_0, false 为 queue_1.is_zero: AtomicBool,/// 用于原子操作,以妥善处理打包与插入的并发问题.concurrent_count: AtomicUsize,}/// 用于 map 和 queue 中共享的交易结构type SharedTx = Arc<TxWrapper>;struct TxWrapper {tx: SignedTransaction,/// 该交易是否被 map 删除,有该标识的交易在打包交易时会被跳过,并且从 queue 中删除removed: AtomicBool,/// 避免重复同步的标识,有该标识的交易在打包 propose 交易时会被跳过proposed: AtomicBool,}/// 用于存储共识同步返回的交易type CallbackCache = Map<Hash, SignedTransaction>;/// Mempool 打包返回给共识模块的数据结构struct MixedTxHashes {order_tx_hashes: Vec<Hash>,propose_tx_hashes: Vec<Hash>,}
通过所有检查的合法新交易在插入 Mempool 时,首先包装为 TxWrapper(removed 和 proposed 均设置为 false)。
进而包装为 SharedTx 插入 TxCache 中(插入轮值 queue 的尾部,以及 map 中)。
Mempool 收到共识的打包请求时,返回 MixedTxHashes,其中包含用于共识的 order_tx_hashes
和用于提前同步的 propose_tx_hashes。
打包算法大致如下:
1. 从轮值 queue 的头部开始依次弹出 SharedTx,
直到全部弹出或者达到 cycles_limit 阈值为止,将这些交易哈希插入 order_tx_hashes 中。
2. 如果第一步结束后,轮值 queue 中还有交易,则继续弹出 SharedTx,
直到全部弹出或达到 cycles_limit 阈值为止,将这些交易哈希插入 propose_tx_hashes 中。
3. 如果第二步结束后,轮值 queue 依然不为空,则继续弹出 SharedTx。
(以上三步弹出的 SharedTx ,按弹出顺序依次插入到替补 queue 中,以维持 SharedTx 插入 Mempool 的顺序。)
4. 当轮值 queue 全部弹出后,交换两个 queue 的角色,即轮值 queue 成为替补 queue,反之亦然。
在打包过程中并发插入的合法新交易都会插入到轮值 queue 中,在 queue 的角色切换之时,
有很小的概率出现少量新插入的交易排在老交易之前,使打包顺序不能完全与交易插入 Mempool 的顺序一致,
但是由于数量极少且很难被利用,因而影响不大。
Mempool 的插入和打包过程如下图所示。